-
Listen, Attend and Spell 논문 리뷰ML/음성인식 2020. 4. 8. 16:19반응형
3. Model

LAS 모델은 acoustic features를 입력으로 사용하고, 영문자가 출력으로 나온다. X = (x1, ..., xT)는 필터 뱅크 기반 features sequence고, Y = (<sos>, y1, ... , yS, <eos>)는 {a, b, c, ... z, 0, ... , 9, <space>, <comma>, <period>, <apostrophe>, <unk>}로 이루어진 문자들의 sequence다. sos는 start-of-sentence token, eos는 end-of-sentence token을 뜻한다.

모델의 출력 yi는 각 문자가 나올 확률을 나타낸다. 이 확률은 이전 문자의 확률을 다 고려했을때 현재 어떠한 문자가 나올 확률이 가장 큰지를 표현한다. 이전에 나온 문자들의 확률을 chain rule을 이용해 곱한 형태로 구해진다.

LAS 모델은 listener와 speller로 이루어져 있다. Listener는 acoustic model encoder고, speller는 attention-based character decoder다. Listen function은 원래 신호 x를 high level representation인 h로 바꾼다. 여기서 h의 길이는 x보다 같거나 짧다. 반면에 AttendAndSpell function은 h로부터 character sequence의 확률분포를 만든다.
3.1 Listen
Listen 연산에서는 피라미드 구조의 Bidirectional Long Short Term Memory (BLSTM)이 사용된다. 이러한 구조를 사용하는 이유는 입력 x의 길이를 h의 길이만큼 줄이기 위함이다. pBLSTM을 이용하면 입력 길이 T에서 U로 줄어드게 된다.
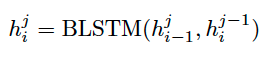
기존의 BLSTM은 이전 스텝과 이전 레이어를 입력으로 사용한다.

하지만 pBLSTM은 이전 스텝과 이전 레이어의 스텝 2개를 입력으로 사용한다. 이전 레이어의 스텝을 2개 사용하면서 time resolution이 절반으로 줄어든다. 이것은 attention model에서 짧은 길이로부터 유의미한 정보를 추출하는것을 가능케 한다. 또한 resolution을 줄임으로써 딥한 구조의 모델이 nonlinear한 feature를 학습하는 것을 가능하게 한다. pBLSTM은 시간 복잡도 또한 줄여준다.
3.2 Attend and Spell
AttendAndSpell function은 attention-based LSTM transducer를 사용한다. 매 output step마다, transducer는 이전에 나왔던 문자들의 확률을 고려해 다음에 나올 문자의 확률분포를 계산한다. y_i의 분포는 decoder state s_i와 context c_i의 함수다. decoder state s_i는 이전 state s_i-1과 이전에 출력된 y_i-1과 context c_i-1의 함수다. context vector c_i는 attention mechanism에 의해 생산된다.

CharacterDistribution은 문자를 출력하는 softmax output을 가진 MLP이고, RNN은 2 layer LSTM이다.
매 time step i마다, attention mechanism에서 AttentionContext는 context vector c_i를 만든다. c_i는 다음 문자를 만들기 위해 필요한 음성 신호에서 정보를 encapsulating한다. Attention model은 content 기반이다. Decoder state s_i의 contents는 attention vector a_i를 만들기 위해 h의 time step u를 나타내는 h_u의 contents에 매치된다. a_i는 c_i를 만들기 위해 vectors h_u를 선형적으로 섞는데에 사용된다.
매 decoder time step i 마다 AttentionContext는 h_u와 s_i를 사용하여 scalar energy e_i,u를 계산한다. Scalar energy e_i,u는 softmax를 사용하여 a_i의 확률분포로 바뀐다. 이는 listener features를 선형하게 섞음으로써 context vector c_i를 만들기 위해 사용된다.

s_i와 h_u를 감싸고 있는 함수는 모두 MLP 네트워크다. a_i의 분포는 전형적으로 매우 날카롭고, h의 몇 프레임에 집중되어있다. c_i는 h의 weighted feature의 continuous bag이라고 볼 수 있다.
반응형'ML > 음성인식' 카테고리의 다른 글
Kaldi 예제 Voxforge 데이터 (0) 2020.01.21 Kaldi, Kaldi gstreamer 설치 및 예제 실행 (0) 2020.01.21 Phoneme recognition (Spikegram, MFCC, Spectrogram, Melspectrogram) (0) 2020.01.21 Speech Emotion Recognition 연구 기록 (0) 2020.01.21